The "Great Debate" is a very emotional exchange that has been running continuously since the late '70s. On some newsgroup somewhere, you will find a thread discussing this topic; although you will have the best luck looking at the Internet comp.lang.asm.x86, comp.lang.c, alt.assembly, or comp.lang.c++ newsgroups. Of course, almost anything you read in these newsgroups is rubbish, no matter what side of the argument the author is championing. Because this debate has been raging for (what seems like) forever, it is clear there is no easy answer; especially one that someone can make up off the top of their head (this describes about 99.9% of all postings to a usenet newsgroup). This page contains a series of essays that discuss the advances of compilers and machine architectures in an attempt to answer the above question.
Although I intend to write a large number of these essays, I encourage others, even those with opposing viewpoints, to contribute to this exchange. If you would like to contribute a "well thought out, non-emotional essay" to this series, please send your contribution (HTML is best, ASCII text is second best) to
rhyde@cs.ucr.edu
Despite the progress made in AI over the years, compilers are not intelligent. Indeed, they are maddingly deterministic. Feed the same inputs to a compiler over and over again and you're going to get exactly the same output. Human beings, on the other hand, are somewhat non-deterministic. Feed a human being the same problem three times and you're likely to get three different solutions. The greatest advantage to using a compiler is that such systems are preprogrammed to handle massive amounts of detail without losing track of what is going on. Human beings are incredibly poor at this task and often seek shortcuts. These shortcuts are often divergences that result in a new and unique solution that is better than that produced by a deterministic system[1]. A good programmer, seeking the most efficient solution to a problem, will often solve the problem several ways and then pick the best solution. Although compilers do a little of this, it's at a much lower level where the payoff isn't so great.
It is common to hear the anti-assembly language crowd claim that assembly language is a dead issue because humans cannot possibly schedule instructions, keep track of lots of registers, and handle all the cycle counting chores as well as a compiler; particularly across a large software system. You know what? They're right. And if this was the way assembly language programmers applied optimizations to any but the most frequently executed statements in a small program, compilers would be winning hands down. Humans simply cannot keep track of lots of little details as well a compiler can. Oh, for short sequences, humans can do much better than a compiler, but across a large program? No way. Fortunately (or unfortunately, depending on how you look at it), this isn't the way assembly language programmers manage to write fast code.
Consider for a moment the lowly compiler. The job of a compiler is to faithfully convert your HLL code into a form the machine can execute. As a general rule, the only optimizations that people find acceptable are those that involve a better translation from the HLL to machine code. Any other changes or transformations to the code are out of the question. For example, suppose you coded a insertion sort in C. Would it be acceptable for your C compiler to recognize the insertion sort and swap a merge sort in its place? Of course not. As a general rule, most people would not allow their compilers to make algorithmic changes to their code. Returning to the example above, perhaps you chose the insertion sort because the data you intend to sort is mostly sorted to begin with. Or, perhaps, you're sorting a small number of items. In either case, the insertion sort may be able to outperform the merge sort implementation even though the reverse is more often true.
Of course, the first argument the uninitiated make when claiming you shouldn't use assembly language to optimize your code is that you should simply choose a better algorithm. There are two problems with this argument: (1) Finding a better algorithm isn't always possible or practical, and (2) why can't the assembly language programmer use that better algorithm as well? Indeed, this second point leads in to the main point of this essay - while any algorithm you can implement in a HLL like C can also be implemented in assembly language, the reverse is not generally true[2]. There are some algorithms that lead themselves to easy implementation in an assembly language that are impossible, or very difficult, to implement in a HLL like C. Often, those algorithms that are easy to express in assembly language are the ones that produce better performance.
It is common knowledge that there are high-level optimizations (e.g., choosing a better algorithm) and low level optimizations (e.g., scheduling instructions). My experience indicates that there are far more than two different levels of optimizations. Indeed, there is probably a continuous spectrum of optimization types rather than a finite (and small) set of optimizations possible. However, for this essay I will assume we can break the world of optimizations into three discrete pieces: high-level optimizations, intermediate levels of optimization, and low level optimizations. One important fact about these levels of optimization is that the higher the level, the greater the promise of improved performance.
A classic example of multiple optimization levels occurs in a program that sorts data. At the highest level of optimization, you must choose between various sorting algorithms. Depending on the typical data you must sort, you might choose from among the bubble, insertion, merge, or quicksort algorithms (hint to those who weren't paying attention in their data structures class, a bubble sort isn't always the slowest algorithm). Your choice of the sorting algorithm will have a very big impact on the overall system performance. For example, if your data set contains just the right values, a 1,000 record database could require 100 times as long to sort if you choose an insertion sort over a merge sort. Let's assume you have the wisdom to choose the best algorithm for your particular application.
As you're probably aware, sorting algorithms that involve comparing data elements require between O(n*lg(n)) and O(n**2) operations to complete. Asymptotic (e.g., Big-Oh) notation is generally one of those concepts that students tend to study weakly in their college courses; they get out into the real world and forget all the details associated with the Big-Oh approximation to running time. In particular, most students forget about the effects of the constant associated with the asymptotic approximation. While polynomial or even exponential performance improvements are possible with better algorithms, most applications in the real world are O( F(n) ) where F(n) <= n (sorting being an obvious exception). Few real-world applications use algorithms that are O(n lg n), much less O(n**2) or O(2**n). Therefore, most real-world speed-ups involve attacking the constant associated with Big-Oh notation rather than attacking the polynomial function. Remember, two algorithms can be O(n) even if one application is always 100 times faster than the other. I don't know of too many programmers who wouldn't rather have their programs run 100 times faster of the cost of implementation wasn't excessive. Attacking the constant falls into the intermediate and low-level optimization classes.
Let's return to the sorting example. A high-level optimization would consist of choosing one algorithm with better performance characteristics than another algorithm under consideration. Very low level optimization consists of choosing an appropriate sequence of machine instructions to implement the sorting algorithm. At this very low level, you must consider the effect of instruction scheduling on the pipeline, the effect of data access on the cache, the number of cycles each instruction requires, which registers you must use to hold live data, etc. As the pro-compiler group properly points out, keeping track of this much global state information all but the shortest assembly sequences is beyond most humans' capabilities.
In-between these two extremes are certain optimizations (medium level optimizations) that would probably never be done by a compiler but are fairly easy to implement. For an example, consider the sorting algorithm discussed earlier. Suppose you are sorting an array of records and the records are rather large. If each record consumes a large number of bytes, it might take a significant amount of time to swap array elements that are out of place. However, if you create an array of pointers (or indexes) into the array of records to sort and use indirection to access the data, you can speed up your sort quite a bit. Such algorithms only produce constant (multiplicative) improvements. But who wouldn't like to see their program run five or ten times faster? Note that these types of optimizations could never be done by a compiler (maybe you really do require the sort to physically swap the array elements), any more than one would expect a compiler to choose a better algorithm.
To summarize, the choice of one high-level algorithm over another may produce dramatic differences in execution time. Choosing a different algorithm may change the basic function that describes the execution time of the program (e.g., from exponential down to polynomial, from polynomial down to linear, from linear down to logarithmic, or from logarithmic down to constant). Most other optimizations only affect the constant in the Big-Oh equation. So they do not have the ability to produce as large an improvement.
Medium level and low-level optimizations attack the constant in the Big-Oh equation. Low-level optimizations typically cut this constant in half or maybe even divide it by four. For example, if you perfectly schedule all your instructions in a pipeline or on a superscalar machine, you would eliminate stalls, thereby speeding up your program by the number of stalls present before the optimization (this is generally 1/2 of the time for architectures circa 1996). It would be very rare to find such low level optimizations improving the performance of a program by an order of magnitude.
Medium-level optimizations, on the other hand, might have a larger impact on the performance. Consider, again, the sorting example. If every comparison the sorting algorithm does requires that you swap data, and your records consume 400 bytes each, it will take you about 100 times longer to sort the data by actually swapping the records than it would to swap pointers to the data. This is a dramatic difference[3].
Okay, what's this got to do with assembly vs. HLL programming? Although assembly language programmers can use arrays of pointers, so can HLL programmers. What's the big deal? The big deal is simply this: there are many intermediate level optimizations that are possibly only in assembly language. Furthermore, many intermediate optimizations, while possible in a HLL, may only be obvious in assembly language.
Let me begin with an optimization that is not really possible in a HLL. A while back, I gave my assembly language students the task of writing a tic-tac-toe program in assembly language. This turned out to be a major programming assignment for them. Many of the students got stuck, so I advised them to first write the program in C++ (to be sure they could solve the problem) and then convert the C++ program, manually, into assembly language. A typical solution using this approach was between 800 and 1,000 lines of 80x86 code. In order to demonstrate that an experienced programmer wouldn't need to write such a large program, I began writing a series of solutions to this problem in assembly language. Now understand one thing, my goal was not to write the fastest or shortest implementation of this program (a lookup table version would probably claim this prize), I was mainly interested in demonstrating that there are many different ways to implement a solution in a given programming language, with some solutions being better than others. One novel solution I created used boolean logic equations (see Chapter Two of the Art of Assembly Language Programming for details on boolean logic) to define the moves. Another solution parsed a series of regular expressions that defined the moves. Yet another solution involves the use of a context free grammar. Of course, there was the ubiquitous look up table version.
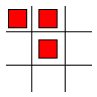
During the implementation of the Tic-Tac-Toe solution, I took advantage of the fact that one really only needs to concerning placing an "O" in one of the following three squares:
To handle any other move, one need only rotate the board 90 degrees and check these three squares on the resulting game board. By repeating this process four times, you can easily check all squares on the board. In a HLL like C++ or Pascal, students typically create an array to hold the Xs and Os that appear on the board and then physically rotate the board by moving characters around in the array.
While implementing the boolean equation version of the Tic-Tac-Toe solution, I discovered that I could use two nine-bit values to represent the Tic-Tac-Toe game board. One of the nine-bit arrays would hold the current X moves, one nine-bit array would hold the O moves. By logically ORing these two nine-bit arrays (that I actually stored into a pair of 16-bit words) I was able to determine which squares were occupied and which were empty. By using bits zero through seven in the word to represent the outside edges of the game board and using bit eight to represent the center square, I was able to do the board rotate operation with a single 80x86 machine instruction: ROL. If the AX register contained the TTT array of bits, then the "ROL AL, 2" instruction did the board rotation that I needed. Contrast this with the number of machine instructions a compiler would generate to rotate the board as an array of bytes. Even if you use the bitwise operators in C, it is unlikely a good compiler would recognize this sequence and generate a single instruction from it (I am not willing to say impossible, just unlikely).
By now, you're probably saying "who cares? Do we really need an efficient version of the TTT game and if we did, why not use a lookup table (that probably would be faster)?" Fair enough. But you see, the point of this discussion is not that I can develop a slick TTT game. The point I'm trying to make is that assembly language programmers have certain options available to them that simply are not available to HLL programmers. Those options represent the main reason it is generally possible to write faster and/or shorter code in assembly language.
Of course, not all intermediate level optimizations are possible only in assembly language. Some of them are possible in certain HLLs as well. The classic example I can think of is the implementation of the Berkeley C Standard Library string package for 32-bit processors. Consider the standard implementation of strcpy:
char *strcpy( char *dest, char *src )
{
char *Result = dest;
_while( *src != '\0' ) /* uses the "randy.h" macro pkg */
*dest = *src;
++dest;
++src;
_endwhile
return Result;
}
(Note that a typical definition merges nearly then entire function into the while loop, e.g., "while( *dest++ = *src++ );" It sacrifices readability for no good reason. Almost any modern compiler will optimize the [more readable] version I've given to emit the same code as the typical implementation. If your compiler cannot do this, you have absolutely no business trying to claim compilers emit code as good as a human).
As any advanced assembly language programmer will tell you, the strcpy routine above could actually run four times faster on a 32-bit processor if you were to move 32-bit quantities on each loop iteration rather than one-byte quantities. The resulting code is difficult to write (at least, correctly) and difficult to debug if there are errors in it, but it does run much faster. The Berkeley strings package does exactly this. The resulting code is many times faster than conventional code that only moves a byte at a time. Note that the Berkeley code is even faster than an assembly version that only moves a byte at a time. Of course, 80x86 assembly programmers can write faster code (I've improved on the Berkeley package on an NS32532 processor, I haven't done this on the 80x86 yet), so this is no proof that C generates code as good as an assembly programmer, but it does demonstrate that some intermediate level optimizations are possible in HLLs, as well.
Note, however, that the optimizations found in the Berkeley string package are not obvious to a C programmer, but they are quite obvious to an assembly language programmer. Indeed, I suspect the original designer of the Berkeley C strings package was very familiar with assembly language or, at least, computer architecture. Therefore, although some intermediate level optimizations are possible, it is unlikely that most HLL programmers would recognize the opportunity to use them, unless, of course, that HLL programmer was also an accomplished assembly language programmer. On the other hand, many of these intermediate level optimizations are quite obvious to an assembly language programmer, so you will often find them in a well-written assembly language program.
Often, I hear the argument "Optimization in assembly language is futile. Today, members of an architectural family are rapidly changing. And the rules for optimization change with each member of the family. An assembly language programmer would have to rewrite his/her code when a new CPU comes along; a HLL program, on the other hand, need only recompile his/her code." This statement generally applies to low level optimizations only. True, CPU family members differ widely with respect to pipelining, superscalar operation, the number of cycles for a given instruction etc. Any assembly language programmer who attempts to optimize his/her program by counting cycles and rearranging instructions is probably going to be disappointed when the next CPU arrives. However, my experience is that very few assembly language programmers write code in this fashion for any program except the most speed sensitive applications. As the HLL people are fond of pointing out, it's just too much work. I will glady concede that compilers, overall, will pick more optimal instruction sequences than I am willing to generate for a typical assembly language program I write. Yet programs I write for the 486, that outperform compiled programs on the 486, still outperform their counterparts on the Pentium (my assembly code goes unchanged, the compiled code is recompiled for a Pentium)[4]. Why is this? Shouldn't the compiled Pentium code run faster because of the superscalar nature of the code? Yes, it does. Typically between 25% and 50% faster. However, my assembly code was five times faster than the original 486 code, so doubling the speed of the compiled code still produces a program that is much slower than my unchanged assembly code.
Of course, I can see some readers out there doing some arithmetic and claiming "Hey, sooner or later the compiled code will beat you." However, such readers are not in tune with recent architectural advances. The current trend in superscalar/pipelined architectures is "out of order execution." This mechanism will reduce the impact of instruction scheduling on a program. That is, the CPU will automatically handle much of the instruction scheduling concern. Therefore, future compilers that spend considerable effort rearranging instructions will not have a tremendous advantage over code that has not been so carefully scheduled (e.g., hand written assembly language). In this case, architectural advancements will work against the compilers.
I would point out that much of the preceding discussion is moot. You see, the arguments the pro-HLL types are advancing assume that these wonderful compilers exist. Outside of laboratories and supercomputer systems, I have yet to see these wonderful compilers. What I have found is that some compilers perform certain optimizations quite well, different compilers perform other optimizations quite well, but no compiler I've personally used combines all these techniques into a single system (of course, certain optimizations are mutually exclusive with respect to other optimizations, so this goal isn't completely achievable). Furthermore, I have yet to see a fantastic compiler that generates good Pentium-optimized code. The current (1996) crop of compilers lose steam beyond the set of possible 486 optimizations. I personally haven't looked at the Pentium Pro and how optimization on that chip differs from the Pentium, but if there are any differences at all, I could easily believe that a Pentium Pro specific compiler will never appear. You see, compilers are examples of programs that are CPU architecture sensitive. While the Pro-HLL types are quick to point out that assembly programmers rarely upgrade their software to a new architecture, they seem to forget that compilers suffer from the same problems (even though compilers are not typically written in assembly language). You can talk about how all you've got to do is recompile your code to get "Pentium-optimized" programs until you're blue in the face. But if you don't have a Pentium optimized compiler, you're still generating 486 (or earlier!) code and it isn't going to compete well with assembly code from that same era.
Perhaps you're going to claim "hey, the compiler on my XXXX RISC workstation is really hot. You're assembly code on the x86 is going to run slower than my HLL code." That's probably true, but you're comparing apples to oranges here. After all, one would expect code on a 500 MHz Alpha to outperform my assembly code on a 66 MHz 486. The real issue here, is the market. If my code performs well on a 66 MHz 486, I will sell a lot more copies than your program that runs on a 500 MHz Alpha. The bottom line is this, if you can afford to limit your market to UNIX-based RISC workstations (note that I am specifically exempting the Macintosh here), go for it. You probably won't need assembly language and whether or not assembly is faster is a moot point. "The rest of us," however, don't have the luxury of developing software on these blazing fast machines. The compilers available to us lowly x86 and PowerPC programmers don't come close to matching what assembly programmers can do (I will leave it up to others to debate whether those RISC workstation compilers are truly better than PC compilers).
To summarize, assembly language programmers do not write faster programs that a HLL compiler produces because they are better at counting cycles and rearranging instructions. Although it is possible for a human to produce a better sequence than a compiler, we're only talking about a factor of two or three here. It is hardly worth the effort to write code in this fashion (unless you're really up against the wall with respect to performance). Furthermore, code written in this fashion has all the drawbacks your college professor warned you about: it's hard to read, hard to understand, hard to maintain, and grows obsolete with the next release of the CPU.
Real assembly optimization occurs at the intermediate level. Intermediate level optimizations are often machine independent, are almost always CPU family member independent, and generally produce much better results (in terms of performance gains) than low level optimizations. Furthermore, you rarely have to sacrifice readability, maintainability, or portability (within the CPU family) to achieve good results.
Often, you will hear someone refer to the "Assembly language paradigm" or "thinking in assembly vs. thinking in C." These phrases are referring to the types of intermediate level optimizations that assembly language programmers often employ. Because most HLL programmers (especially those who argue against the use of assembly language) do not have sufficient experience with these intermediate optimizations to fully appreciate them, it is very difficult for a diehard assembly language programmer to convince a diehard HLL programmer that there really is something special about assembly language programming. Hopefully, this essay has helped articulate some of the advantages of assembly language programming.